INT J MED INFORM | 从斑马鱼到人类患者:大模型 + 癫痫本体论,攻克Dravet 综合征药物信息提取痛点
时间:2025-09-25 15:44:02 热度:37.1℃ 作者:网络
Dravet综合征是一种发育性和癫痫性脑病,通常在婴儿期出现严重的运动性癫痫发作,并且对多种抗癫痫药物表现出高度耐药性,同时伴随多种并发症,这种罕见儿科癫痫的治疗和药物研发面临巨大挑战,尤其是如何从大量已发表文献中系统提取药物疗效数据,以桥接临床前模型与人类表型之间的差距。近年来,大型语言模型在自然语言处理任务中展现出强大能力,但在专业医学领域尤其是罕见病方面,其性能仍不尽如人意,主要原因在于模型缺乏领域专业知识、语义理解不一致以及需要大量标注数据进行优化,而罕见病数据稀缺进一步限制了模型的应用。因此,如何在不依赖大量标注样本的情况下提升大型语言模型在医学文本处理中的准确性和可靠性,成为当前研究的重要方向。

本研究提出了一种结合专家构建的本体论与分阶段上下文学习的新方法,旨在优化大型语言模型在Dravet综合征文献中的药物疗效信息提取任务。研究首先基于Griffin等人2018年发表的综述构建了一个包含17种抗癫痫药物在人类患者、scn1lab斑马鱼模型和Dravet综合征小鼠模型中疗效数据的基准数据集,该数据集不仅涵盖了药物对自发性癫痫和诱发型癫痫的疗效,还记录了特定诱发因素如温度和光刺激,为评估临床前模型的预测有效性提供了重要基础。为了提升模型对复杂医学概念的理解,研究团队联合基础科学家和临床神经学家开发了Dravet综合征癫痫本体论,该本体论扩展自已有的癫痫与发作本体论,涵盖了基因变异类型、脑区与细胞类型、精神行为诊断、睡眠结构、学业表现以及国际抗癫痫联盟最新分类系统等七个核心维度,并通过两轮迭代建模和专家研讨会不断完善,最终包含2169个类和8758条公理,成为目前临床应用中规模最大的癫痫领域本体论资源。
表1 研究中使用的基准数据集,表示17种ASM在DS患者和两种动物模型(scn1lab斑马鱼和小鼠模型)中的疗效,结果以本体嵌入PCL提示生成的数据(分子)与Griffin等人综述中报告的原始专家生成数据(分母)的比率表示
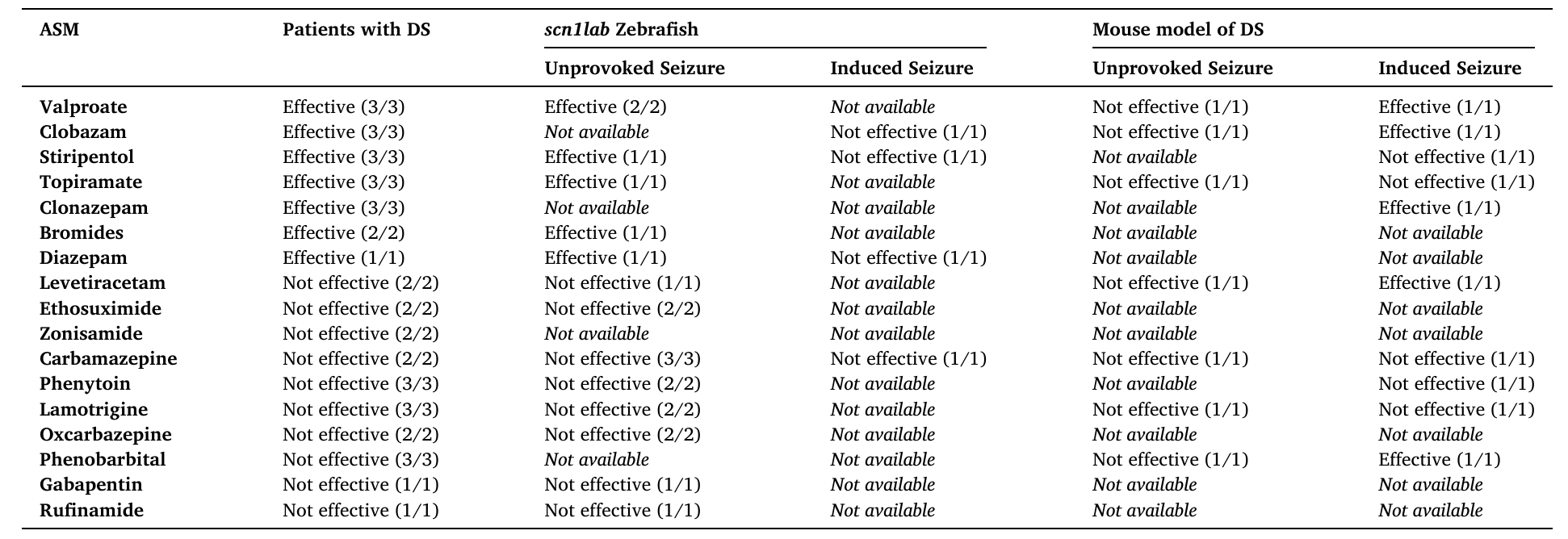
在方法层面,研究团队设计了分阶段上下文学习框架,将复杂的药物疗效提取任务分解为四个顺序执行的阶段,包括抗癫痫药物识别、模型系统与患者标识、癫痫类型分类以及药物疗效数据提取,每个阶段通过少量示例进行上下文学习,逐步引导模型完成信息抽取。然而,初步实验表明,仅使用分阶段上下文学习虽然将基线提示的准确率从47%提升至72.5%,但仍存在术语不一致和医学推理错误等问题。为此,研究进一步将Dravet综合征癫痫本体论以程序化方式集成到分阶段学习提示中,通过引入本体论中的类层次结构、同义词映射和标准化术语,如“自发性癫痫”和“刺激诱发癫痫”及其子类,显著增强了模型对医学实体的识别能力和语义一致性。此外,本体论中还包含了药物与RxNorm标准编码的映射、模型系统的详细分类以及癫痫发作特征的精确定义,使得模型在处理多药物研究或复杂转化实验时能够更准确地进行推理。
研究结果显示,本体论的引入显著加速了Gemini 1.0 Pro大型语言模型的少样本学习能力。在零样本学习设置下,基线提示和分阶段上下文学习提示的表现均较低,而在仅使用两个示例进行少样本学习后,本体论增强的分阶段上下文学习提示在四个查询组件上均达到100%的准确率,完全复现了基准数据集中17种抗癫痫药物在人类和两种动物模型中的疗效数据。具体而言,模型能够正确区分药物在不同模型和癫痫类型中的疗效差异,例如丙戊酸钠在人类患者中有效,但在小鼠模型中对自发性癫痫无效;氯巴占在人类中有效,而在斑马鱼模型中对诱发型癫痫无效。相比之下,未使用本体论的提示方法即使在少样本学习下仍存在显著错误,尤其是在药物识别和疗效判断方面。这一结果表明,本体论作为外部知识模型,不仅提升了模型的语义理解能力,还大幅减少了优化所需的数据量,为在数据稀缺的医学领域中应用大型语言模型提供了可行路径。
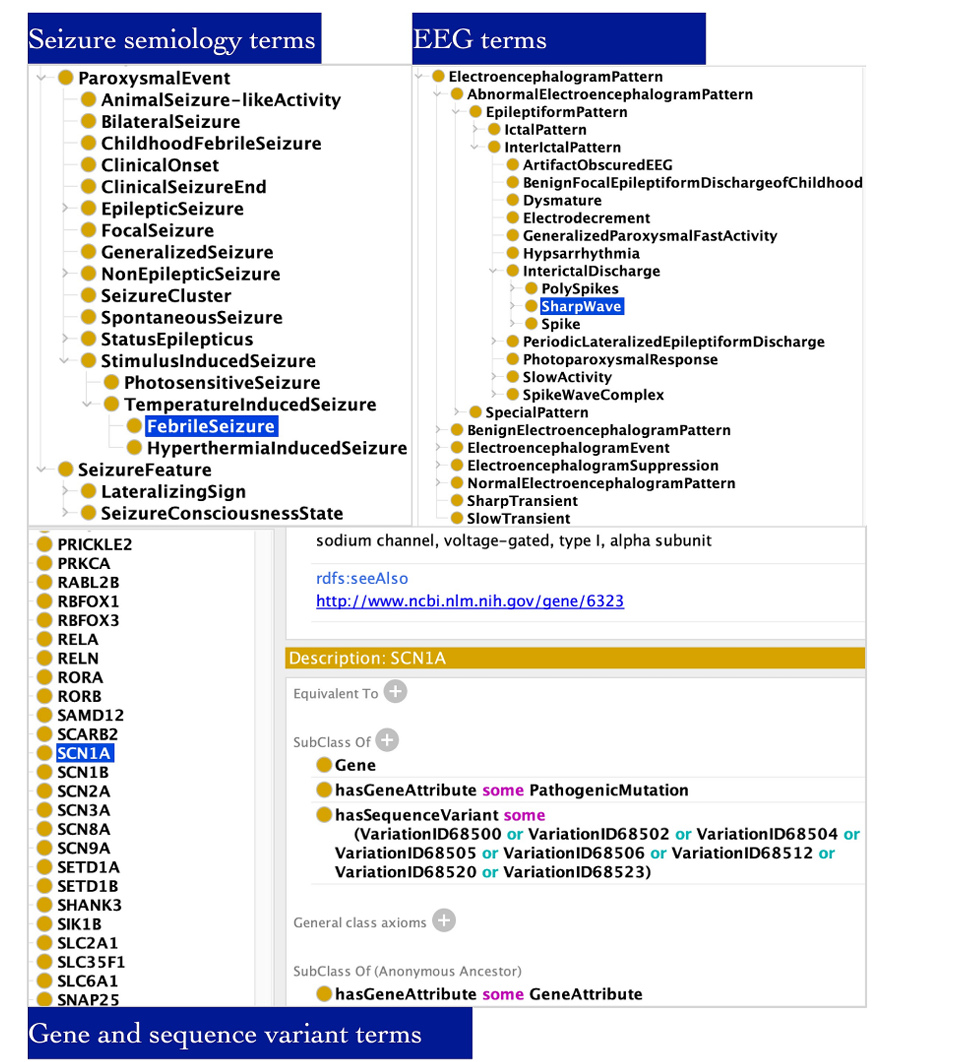
图1 DS癫痫本体论以细粒度建模了DS基因型和表型信息,包括发作症状学术语、脑电图模式以及与基因相关的序列变异,如SCN1A及其与NCBI基因数据库的映射
为了验证方法的可扩展性,研究团队进一步从PubMed Central检索了4935篇与Dravet综合征相关的文献,经过自动分类和人工筛选后,最终纳入75篇原创性研究进行独立验证。使用本体论增强的分阶段上下文学习提示,模型成功提取了这75篇文章中17种抗癫痫药物的疗效信息,并经人工核对确认准确率为100%。分析结果显示,多个药物在不同研究中的疗效报告存在明显不一致,例如丙戊酸钠、氯巴占、司替戊醇等九种药物在人类研究中既被报告有效也被报告无效,在动物模型中也出现类似矛盾。此外,研究还发现当前对某些药物的疗效认知存在空白,例如氯硝西泮在斑马鱼和小鼠模型中的自发性癫痫疗效尚未被评估,而唑尼沙胺在临床前模型中缺乏相关实验数据。这些不一致性和空白点为未来实验设计提供了重要参考,例如可通过更大样本的人类研究或针对性动物实验验证矛盾结果,或基于现有数据提出新假设,如奥卡西平在模型系统中对自发性癫痫无效。
在方法通用性测试中,研究还提取了七种非抗癫痫药物(如芬氟拉明、氯卡色林、大麻二酚等)的疗效信息,结果显示大麻二酚在17项人类研究中一致有效,而索替卡奈在人类和小鼠模型中也表现出疗效,但帕潘立昂在人类和斑马鱼模型中尚无研究数据。这一扩展分析不仅验证了本体论增强方法在新药物筛选中的适用性,也展示了其在快速整合新文献数据方面的潜力,为药物再定位和个体化治疗策略提供了数据支持。总体而言,本研究通过将专家知识嵌入大型语言模型的优化流程,实现了在少量样本下达到人类水平的医学信息提取精度,为罕见病和其他专业医学领域的自然语言处理应用树立了新标杆。
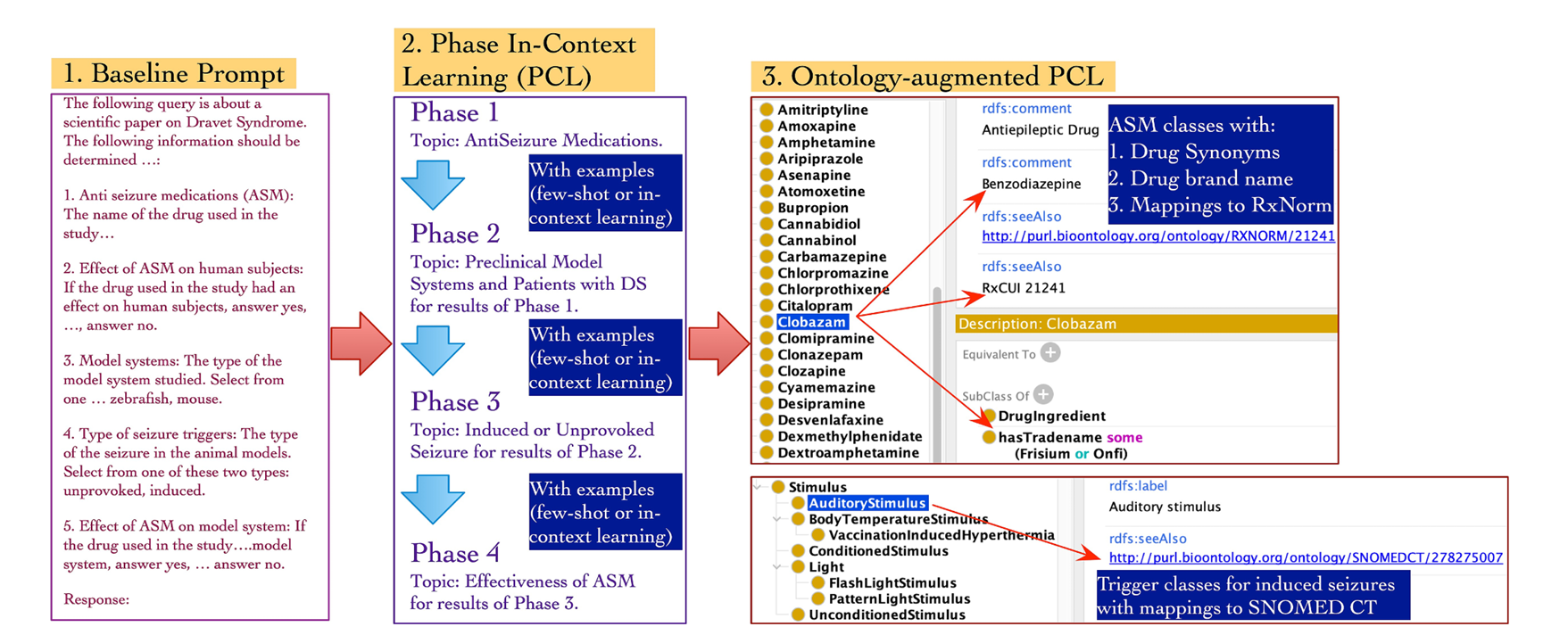
图2 三种提示调优方法的概述:基线提示使用单一表达式提取ASM名称、模型系统名称、癫痫触发因素和ASM疗效;分阶段上下文学习方法;DS癫痫本体论增强的PCL方法
本研究的主要局限在于未充分利用本体论的推理能力进行语义增强和结果一致性检查,也未进行监督微调以进一步优化模型性能。未来工作将探索将描述逻辑推理器与大型语言模型结合,以实现更复杂的医学推理任务,并在更多标注数据可用时结合监督微调提升模型在特定子领域的表现。通过持续整合本体论与先进的语言模型技术,有望在癫痫及其他神经发育性疾病的临床研究和患者护理中发挥更大作用。
原始出处:
Golnari, P., Prantzalos, K., Hood, V., Meskis, M. A., Isom, L. L., Wilcox, K., Parent, J. M., Lal, D., Lhatoo, S. D., Goodkin, H. P., Wirrell, E. C., Knupp, K. G., Patel, M., Loeb, J. A., Sullivan, J. E., Harte-Hargrove, L., Fureman, B. E., Buchhalter, J., & Sahoo, S. S. (2025). Ontology accelerates few-shot learning capability of large language model: A study in extraction of drug efficacy in a rare pediatric epilepsy. International Journal of Medical Informatics, 201, 105942.
本文相关学术信息由梅斯医学提供,基于自主研发的人工智能学术机器人完成翻译后邀请临床医师进行再次校对。如有内容上的不准确请留言给我们。

